CASE STUDY
Text-to-Speech Inference Optimisation on Edge (Under NDA)
This case study describes how TechnoLynx built a real-time Kazakh text-to-speech (TTS) solution using ONNX, deep learning, and multiple optimisation methods, targeting deployment on Android, Windows, and iOS.
Problem
A small government-backed startup, aimed to improve accessibility for individuals with visual impairment by expanding multi-platform screen reading tools to support Kazakh on consumer devices. Kazakh posed specific constraints: it is not widely supported by major platforms, few high-quality pre-trained models exist, and existing tools lacked native support. The client also required fast deployment across Android, Windows, and iOS, with real-time performance and natural-sounding speech under mobile memory and performance limits.
Challenges & Constraints
Limited time
The client had a firm release date, so the work relied on pre-trained Kazakh models rather than training or retraining from scratch.
Format compatibility
Deployment required converting PyTorch models into ONNX (Android/Windows) and CoreML (iOS), including reworking inputs, outputs, and inference pipelines.
iOS memory limitations
The iOS screen reader framework (AVSpeechSynthesisProviderAudioUnit) had strict memory limits that the original model could not meet.
Audio quality
Natural-sounding speech was required, including suitability for formal communication (robotic or artificial tones were unacceptable).
Outdated application layers
Some open-source tools were useful but depended on old build systems and dependencies, requiring updates or rewrites of core components.

Solution
The work focused on two practical questions: how to deploy a Kazakh TTS model on three platforms using existing tools, and how to maintain high-quality, real-time speech under memory limits.
Android & Windows (ONNX)
Converted the PyTorch model to ONNX and optimised model size by reducing layers and quantising weights.
iOS approach (CoreML + standalone)
Because the screen reader framework imposed hard memory limits and the model was too heavy, the iOS delivery was implemented as a standalone app to run outside the system’s built-in memory limits.
Known limitation
The standalone iOS app could not integrate directly with VoiceOver, but it provided full text-to-speech functionality with natural voice quality.
Toolchain
PyTorchPre-trained model checkpoints
ONNX RuntimeAndroid + Windows deployment
CoreML ToolsiOS optimisation
FFmpegAudio pre/post-processing
Xcode + AVFoundationiOS integration
FrameworkAVSpeechSynthesisProviderAudioUnit
ConstraintStrict memory limits; original model could not run within them
WorkaroundStandalone iOS app (no direct VoiceOver integration)
Results
The project ultimately resulted in a high-quality text-to-speech system available on multiple platforms, including Android, Windows, and iOS. While the iOS version required a standalone application due to memory limitations, the overall solution was deemed a success.
230MB → 97MB
Model size reduced from 230MB to 97MB.
320ms → 130ms
Inference time reduced from 320ms to 130ms on average.
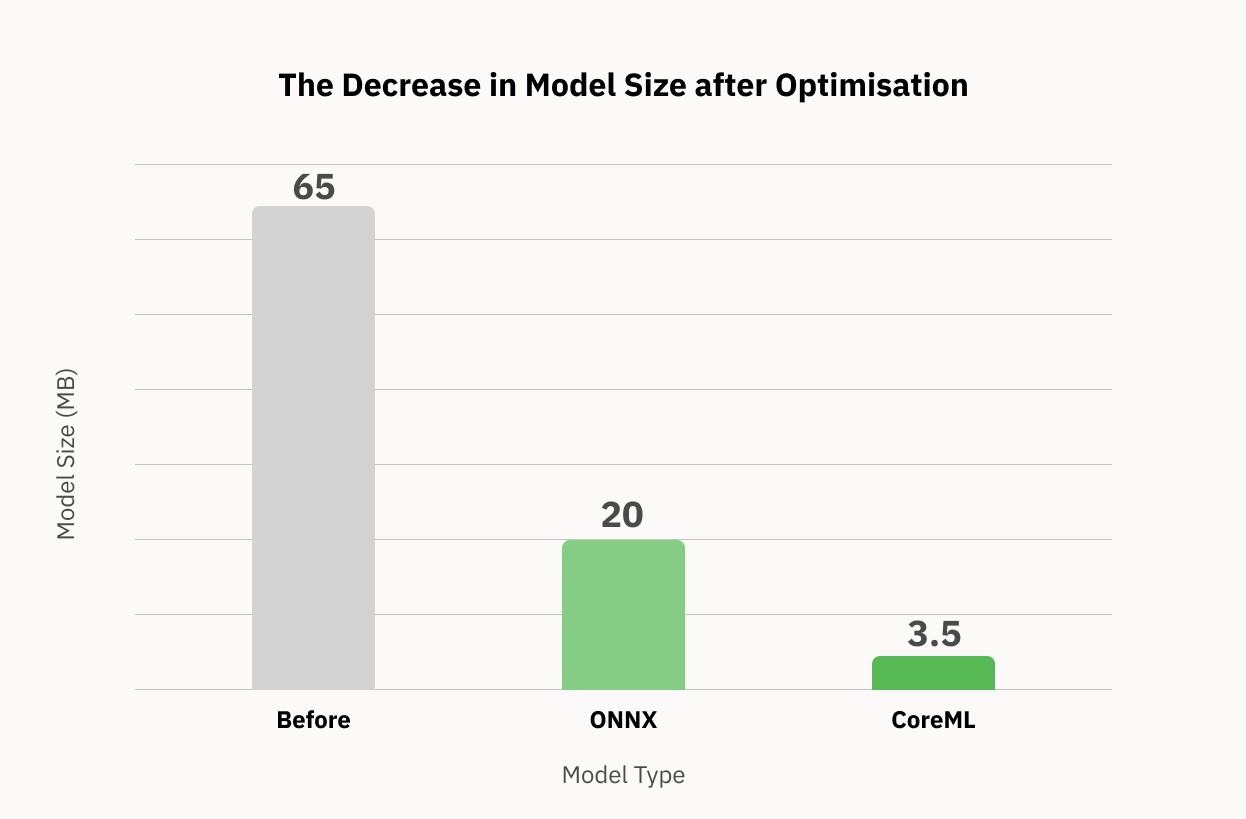
65MB → 20–10MB
Size minimised from 65MB to a set of ONNX models between 20 and 10MB.
CoreML 3.6MB
CoreML model size: 3.6MB.
Outlook and Lessons
This case shows how careful planning and the right tools can solve practical language support problems.
We adapted pre-trained models, updated legacy tools, and worked within device limits.
We can apply the approach we used in this project to other languages or platforms.
Future Steps
Continue to optimise the model for iOS devices, exploring alternative ways to reduce memory consumption.
Future projects could incorporate more advanced deep learning models to enhance the quality of text-to-speech software even further.
Our Technological Capabilities
Computer Vision Services
Our services feature expertise in classical computer vision, human-supervised system design for legal compliance, video pipeline optimisation with tools like FFmpeg, custom adaptable models, and explainable AI for ethical transparency.

Generative AI
We are leaders in generative AI, offering optimised inference for faster deployments, ethical AI systems with bias mitigation, intelligent automation for adaptive workflows, and advanced simulation and prototyping capabilities.

GPU Performance Engineering
We deliver immersive XR solutions with cross-platform development (Unity 6), GPU performance optimisation, and expertise in NVIDIA Omniverse and CloudXR. We also use reinforcement learning for intelligent XR environments.

Building Real-Time TTS for Edge Devices?
If you need to ship an on-device voice solution across platforms, while balancing model size, latency, and quality, we can help you define the right conversion, optimisation, and deployment strategy.