CASE STUDY
Fraud Detector Audit (Under NDA)
TechnoLynx was brought on board to help tackle challenges with an existing fraud detector at a multi-national, medium-sized company, specifically very rare outlier fraud cases with too little data to train the system to recognise them.
The Challenge
These outliers occurred so infrequently that there was not enough data to train the system to recognise them, and missing them could have a substantial impact on operations, customer trust, and financial stability.
Rare outliers, limited training data
These outlier cases occurred so infrequently that there wasn’t enough data to effectively train the system to recognise them.
High-impact failure modes
These rare cases could have a substantial impact on the company’s operations if not detected early, and detecting fraud is crucial for maintaining customer trust and safeguarding financial stability.
Synthetic data as a path to resilience
The client’s initial hypothesis was to generate artificial samples similar to known problematic cases and add them to training to improve resilience.

Image credits: Freepik.
Project Timeline
From synthetic sample generation to a thorough review of the data acquisition pipeline and accuracy metrics
Outlier Framing
Identified a set of very rare outlier fraud cases that posed a serious threat, with too little data to effectively train the system to recognise them.
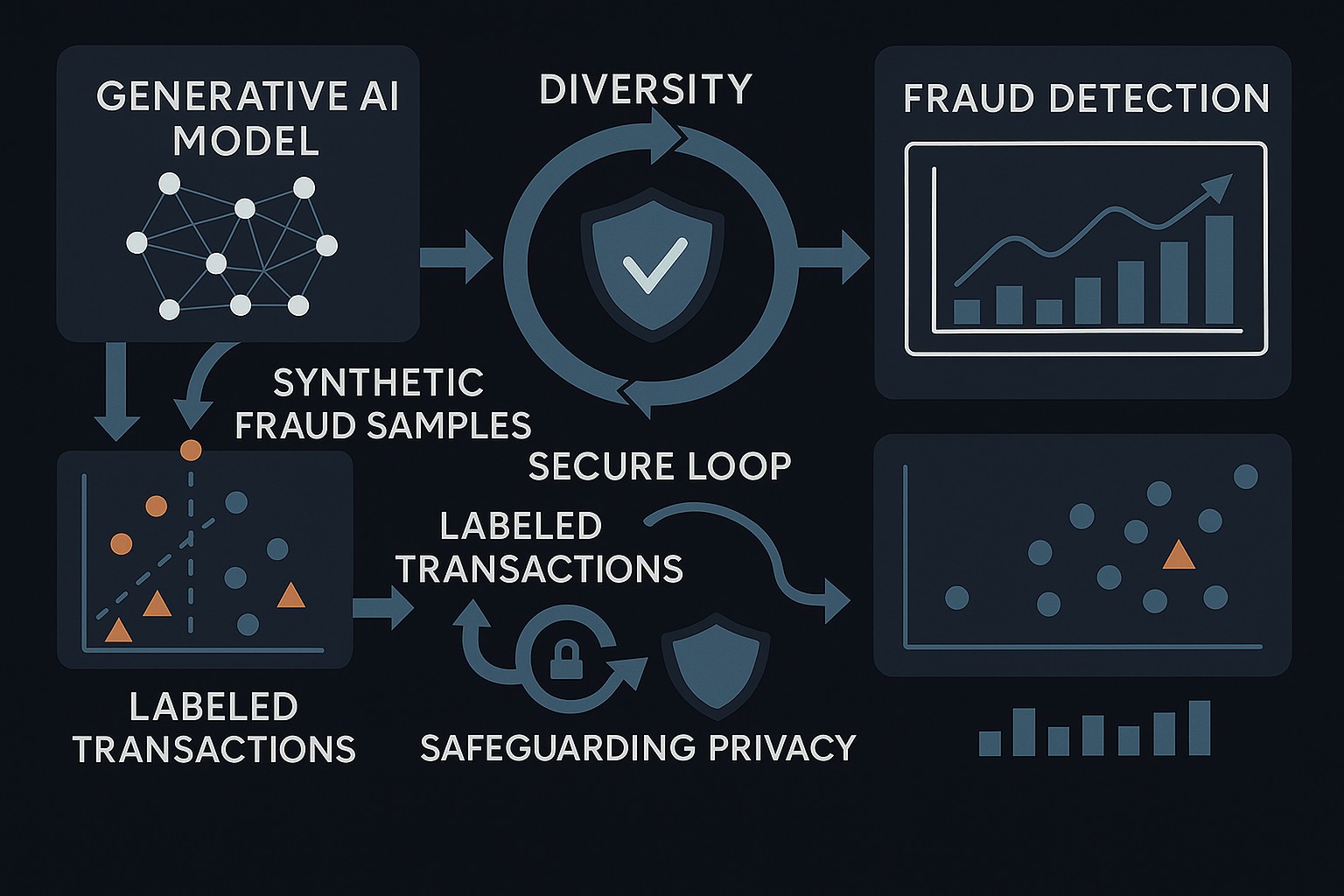
Built a system intended to generate new synthetic samples resembling rare outlier fraud cases using generative model techniques.
Synthetic Generation
Targeted Augmentation
Pivoted to augmenting existing correct/incorrect samples with minor changes designed to fail or pass the current fraud detector, exposing broader resilience gaps.
Tightened collaboration with the client’s internal team and conducted a thorough review of the data acquisition pipeline and accuracy metrics.
Data & Metrics Audit
Recommendations & Adoption
Delivered practical recommendations to improve resilience and measurement; the client implemented them and adopted best practices at a process level.
The Solution
We began within the client’s initial scope: generate synthetic samples resembling rare outlier fraud cases. When the generated samples did not capture the specific fraudulent properties of concern, we pivoted to targeted augmentation and then broadened into a thorough review of the data acquisition pipeline and accuracy metrics.
Generative Models
Built a synthetic-sample generation system using generative model techniques. In practice, generated samples did not exhibit the specific fraudulent properties the client was most concerned about.
Augmentation Pivot
Developed a system to augment existing correct/incorrect samples with small changes designed to fail or pass the current fraud detector, revealing more general resilience issues beyond the originally known outliers.
Audit + Recommendations
Conducted a thorough review of the client’s data acquisition pipeline and accuracy metrics, then delivered recommendations aimed at improving the overall resilience of the fraud detection system.
Technical Specifications
Methods
Generative models for synthetic samples, then targeted augmentation of existing samples
Library
Keras (used for fast prototyping of deep learning models; specific version to meet client requirements)
Constraint
Generative approaches were constrained by the same data scarcity that limited the original model
Challenge
Encountered multiple bugs related to training generative systems (slowed progress)
Tooling
Gradually transition away from Keras for future work; consider alternatives with better stability/performance for this task
The Outcome
The project concluded with a set of final recommendations that the client implemented, introducing a more dependable way to measure fraud model accuracy.
20%+
Increase in fraud detection accuracy
Reported after implementing improved measurement methods and project recommendations.
Key Achievements
Delivered final recommendations that the client implemented to improve overall resilience
Introduced a more dependable method for measuring the fraud model’s accuracy
Reported accuracy improvement of over 20% after adopting the new methods and processes
Improved identification of fraudulent transactions, including rare outlier cases
Best-practice recommendations were adopted at a process level and benefited other client projects
Improved the client’s ability to monitor and manage risks associated with fraudulent transactions
Our Technological Capabilities
Computer Vision Services
Our services feature expertise in classical computer vision, human-supervised system design for legal compliance, video pipeline optimisation with tools like FFmpeg, custom adaptable models, and explainable AI for ethical transparency.

Generative AI
We are leaders in generative AI, offering optimised inference for faster deployments, ethical AI systems with bias mitigation, intelligent automation for adaptive workflows, and advanced simulation and prototyping capabilities.

GPU Performance Engineering
We deliver immersive XR solutions with cross-platform development (Unity 6), GPU performance optimisation, and expertise in NVIDIA Omniverse and CloudXR. We also use reinforcement learning for intelligent XR environments.

Want to Improve Fraud Detection Resilience?
Let’s discuss how stronger data pipelines, better accuracy measurement, and ML-driven approaches can reduce risk from rare outlier cases.